
Benchmarking LLM against "Deceptive & Challenging" text endings benchmark (HellaSwag)
A toy example


Summary of Topics :
Why LLM benchmarking is needed.
What is Hellaswag (Description and Example))
Toy evaluation example (with code).
Next steps
Links
Why LLM benchmarking is needed ?
In my previous post, I have briefly walked through a simple example showing how to spin up a toy server with a simple LLM model.
While I strongly believe the owning a local LLM framework is the way to go for SMEs (see link no. 1 below for reasons) this adds responsibility on AI Engineers to have proper benchmark to see if the model is actually giving acceptable accuracy when performing the task at hand.
There are (literally) hundreds of LLM benchmarks in the LLM-Space (See link 2 below). In general a benchmark can be defined with :
Task : what kind of job the model is expected to do : text completion, summarization, reasoning , math-solving
Dataset : Usually defined as a set of inputs and expected outputs. Usually there is a specific data-source from where this data is generated with some design objective behind the data processing.
Metric : This the quantification of how model’s output (partially) matches or being close to the expected output.
With these three pillars defined, we have a solid benchmark at hand. Usually as any dataset they are split into train,test and validation.
Similar to classic machine learning practice the role of each split is:
Train : might be used not to train but to “tune” the base model, to test how the model performs with or without tuning .
Test : might be used to enhance the tuning process.
Validation : Used to report metrics.
These is the general concept behind most of the benchmarks. Understanding them can help you easily understand existing benchmarks , or even generating your own (see link 3 below).
Hellaswag
So what is it ? Let’s try to understand it given the aforementioned benchmark definition : Task , Dataset and Metric
( 1 ) Task :
Given a (context) text there are 4 possible completions. The task for the model is to choose the most correct completion
» Each sample has the following fields (listing important ons).
ctx : the text to complete (prompt or query to LLM)
endings : 4 possible completions to ctx
label : ranges from 0 to 3 - the numerical index for the correct endingExample
ctx
'The man then lifts the weight over his head and stands up. The man drops the weight, pumps his fist, and walks off. the man'
endings
( 0 )'lifts the weight one more time, lifts it over his head, dumps it into the circle at the end of the circle and walks away.'
( 1 ) 'returns and lifts the weight to his shoulders then over his head.'
( 2 ) 'bends and gets on his knees, picks up a bowling ball, then drops it and goes and hits another bowling ball onto the ground behind him.'
( 3 ) 'then begins acting funny as someone begins from behind.'
Label
1( 2 ) Dataset :
The idea behind hellaswag is to employ Adaptive Filtering (See link 4) : an approach that is designed to generated “deceptive” multi-choice endings to the ctx .
In general this happens by created “false” endings with words that you find in the “true” ending, but the “false” endings are either not making sense or physically impossible.
» For the above example
- Ending 0 has the word lift but inconsistent with itself : how can he dump the weight into and at the end of the circle at the same time ?
- Ending 2 inconsistent object : bowling ball comes into in the scene and why would someone hit a bowling ball ? The correction action with bowling ball is throwing it.
- Ending 3 totally irrelevant : Why would he act funny ? Nothing funny in weightlifting at all.
( 3 ) Metric
This is quite simple in this case : Average Accuracy , for each sample it gets score of 1 to 0, the models gets 1 if it gets the correct answer and 0 if the models gets the wrong one.
Toy Evaluation Example ( with Code)
There are dozens of LLM-evaluation tools that makes the evaluation process relatively straightforward. For example lm-evaluation-harness is on of the most famous LLM-evaluation frameworks that nearly support evaluating hundreds of models (served by vLLM servers) against almost every known LLM-benchmark. (Check link 5)
However, due do the “tutorial” nature of this article, I wanted to keep it simple and get my hands a bit dirty and try to implement the evaluation code in a more basic way.
The following coding snippet can be summarized in the following steps:
load hellaswag dataset sing hugging-face dataset package (loading only the “validation” split)
Sample k examples
I use the Tiny-LLama-chat model as a toy model for this example
For each, calculate the likelihood score for each ending with the given context and select the the ending with the highest likelihood
Calculate average accuracy
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from datasets import load_dataset
import numpy as np
import random
from tqdm import tqdm
from loguru import logger
if __name__ == "__main__":
ds = load_dataset("Rowan/hellaswag",split="validation")
N = ds.shape[0]
k = 5000
indices = [random.randint(1, N-1) for _ in range(k)]
ds_sample = ds.select(indices=indices)
logger.info(f"Loaded dataset with shape = {ds.shape} and selected randomly {k} samples")
# Load model and tokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
logger.info(f"Loaded tokenizer")
model = AutoModelForCausalLM.from_pretrained(model_name)
logger.info(f"Successfully loaded model {model_name}")
model.eval()
correct_selection_count = 0
for sample in tqdm(list(ds_sample.iter(1)),desc="Scoring samples"):
context = sample["ctx"][0]
endings = sample["endings"][0]
scores = []
for ending in endings:
# Combine and tokenize
input_text = context + ending
inputs = tokenizer(input_text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs, labels=inputs["input_ids"])
# CrossEntropyLoss averaged over all tokens
neg_log_likelihood = outputs.loss.item()
# Convert loss to log-likelihood score (optional: multiply by length for total LL)
log_likelihood_score = -neg_log_likelihood
scores.append(log_likelihood_score)
top_scored_index = np.argmax(scores)
if top_scored_index == int(sample["label"][0]):
correct_selection_count +=1
accuracy = float(correct_selection_count)/k
logger.info(f"Accuracy = {accuracy}")
The Github link for the code is in Link 6 below.
And here is a sample output with results
/home/mbaddar/Documents/mbaddar/bf/mbaddar_github_repo/llm-arena/.venv/bin/python /home/mbaddar/Documents/mbaddar/bf/mbaddar_github_repo/llm-arena/sandbox/tinyllama_hellaswag.py
2025-05-29 09:57:53.679 | INFO | __main__:<module>:14 - Loaded dataset with shape = (10042, 10) and selected randomly 5000 samples
2025-05-29 09:57:54.127 | INFO | __main__:<module>:18 - Loaded tokenizer
2025-05-29 09:57:57.509 | INFO | __main__:<module>:20 - Successfully loaded model TinyLlama/TinyLlama-1.1B-Chat-v1.0
Scoring samples: 100%|██████████| 5000/5000 [6:52:36<00:00, 4.95s/it]
2025-05-29 16:50:35.131 | INFO | __main__:<module>:43 -
Accuracy = 0.2576
Process finished with exit code 0
The official score for Tiny Llama against HellaSwag (and other benchmarks ) can be found in link 7 .
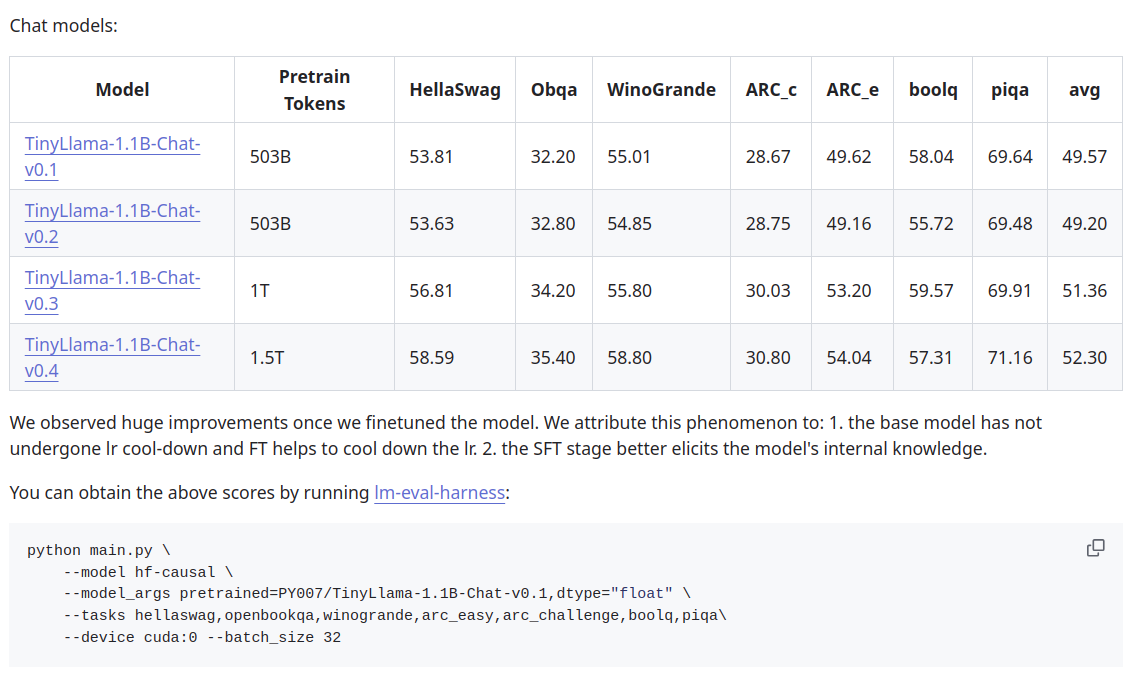
So the accuracy number I have got in my small experiment (25.7%) is quite far from the reported number (53 to 58%). So it seems that it is either because I have used a sample of data or maybe I did something wrong in the evaluation. Anyway, I thought I can share what I have and iterate later to compare the numbers.
Next Steps
Double check the evaluation process and metrics calculation
Show how to use lm-eval-harness and dig deeper into it
If you are interested in the internal of LLM and how to spin up local servers with local LLM models and how to evaluate them, to confidently build your own LLM-application , follow me for more technical-heavy articles. Stay tuned !