
Gemini vs ChatGPT , who wins in the text summarization ?
A case study for Finance Report summarization

In this article
Recap on text summarization and why evaluating it is crucial
Recap on ROUGE metric
The setup I made for testing the quality of LLM-generated summary
Code details
The Problem
When making critical decisions based on a collection of documents, summarization becomes essential. According to the 80-20 rule, 80% of the key information is often concentrated within just 20% of the text. This makes summarization a crucial tool for effective decision-making.
However, the quality of a summary depends on three key factors:
Conciseness: A 10-page summary for a 15-page document may not add much value.
Information Extraction: How much of the truly useful content has been captured?
Relevance to User Intent: The ideal summary varies depending on the context. For instance, given a financial report : summarizing for exploring the overall company performance is totally different than a summary to take a quick buy/sell/hold decision.
The Solution
Hence, having a solid evaluation metric for summarization is essential. Three approaches are common for this task
ROUGE
BLEU
BERT-Score
The scope of this article is to focus on a case study where the ROUGE metric is used. For more details, check my article¹ .
The Experimental Case Study setup
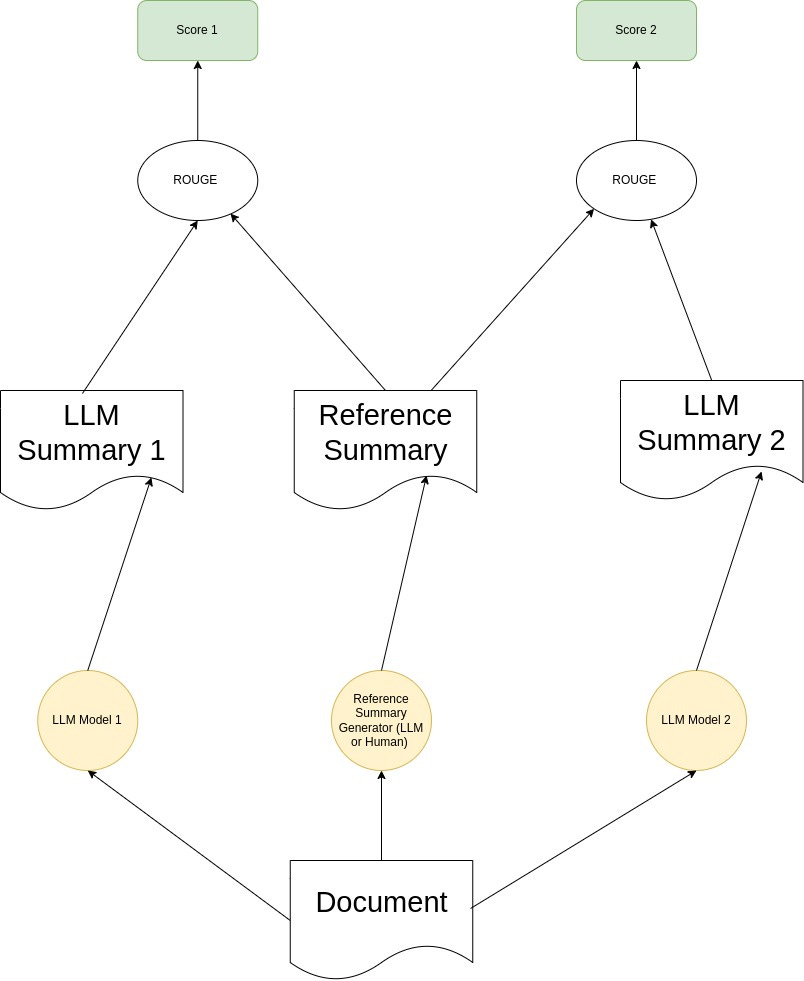
I converted Tesla's SEC 10-K financial report into a text file. To evaluate using the ROUGE metric, we need two summaries: one generated by a model and another by a human expert. For this experiment, I used an LLM-as-Judge approach, where the summaries being tested are generated by OpenAI’s GPT-4o and Gemini models for comparison. On the other hand, the "reference" summary is produced by the Perplexity LLM model acting as the judge.
Here is the GitHub links to the code and datasets :
Dataset:
1. The Tesla 10K report : This is the report used for the experiment, originally can be downloaded from here .
2. The Perplexity one page summary : This is the results for simply asking Perplexity LLM to give one page summary of the report
3. The ChatGPT one page summary : Same as point 2 but for ChatGPT
4. The Gemini one page summary : Same as point 2 but for Gemini.
Code:
I have used the rouge-score package for this experiment. And here is the Python script where I do compare the rouge score for GPT and Gemini based on Perplexity as a judge.
I put the code snippet and output here also for convenience (No syntax highlight in Substack, not my fault :) :
# The code snippet is based on the code an the data in my github repo dir
# https://github.com/mbaddar1/llm/tree/main/summarization/evaluation
# open the summary files
with open("tesla_10k_chatgpt_summary_one_page.txt", "r") as f:
generated_summary_gpt = f.read()
with open("tesla_10K_gemini_summarization_one_page.txt", "r") as f:
generated_summary_gemini = f.read()
with open("tesla_10k_perplexity_summary_one_page.txt") as f:
reference_summary_perplexity = f.read()
with open("tsla-20231231-gen-10K-report.txt") as f:
original_text = f.read()
#------------------------------------------
# setup scorer object
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2'], use_stemmer=True)
#-------------------------------------------
# some statistics about the compression ratio for text.
# This is an objective measure of the value the summarization process
# can add to the user
print(f"Length of original text = {len(original_text)}")
print(f"Length of reference summary (Perplexity) = {len(reference_summary_perplexity)}")
print(f"Length of generated summary (GPT) = {len(generated_summary_gpt)}")
print(f"Length of generated summary (Gemini) = {len(generated_summary_gemini)}")
#-------------------------------------------------------
print(f"Compression ratio of reference summary (Perplexity) = {float(len(reference_summary_perplexity)) / len(original_text)}")
print(f"Length of generated summary (GPT) = {float(len(generated_summary_gpt)) / len(original_text)}")
print(f"Length of generated summary (Gemini) = {float(len(generated_summary_gemini)) / len(original_text)}")
print("ChatGPT summarization rouge scores (ChatGPT vs Perplexity) ")
score_ = scorer.score(target=reference_summary_perplexity, prediction=generated_summary_gpt)
print(score_)
print("Gemini summarization rouge scores (Gemini vs Perplexity)")
score_ = scorer.score(target=reference_summary_perplexity, prediction=generated_summary_gemini)
print(score_)The Output of the Script
Length of original text = 441507
Length of reference summary (Perplexity) = 3678
Length of generated summary (GPT) = 3090
Length of generated summary (Gemini) = 3970
#-----------------------------------------------------------
Compression ratio of reference summary (Perplexity) = 0.008330558745387955
Length of generated summary (GPT) = 0.00699875653160652
Length of generated summary (Gemini) = 0.008991929912776015
ChatGPT summarization rouge scores (ChatGPT vs Perplexity)
{'rouge1': Score(precision=0.45544554455445546, recall=0.37322515212981744, fmeasure=0.41025641025641024), 'rouge2':
Score(precision=0.10669975186104218, recall=0.08739837398373984, fmeasure=0.09608938547486033)}
#--------------------------------------------------------------
Gemini summarization rouge scores (Gemini vs Perplexity)
{'rouge1': Score(precision=0.490787269681742, recall=0.5943204868154158, fmeasure=0.5376146788990827), 'rouge2': Score(precision=0.2348993288590604, recall=0.2845528455284553, fmeasure=0.25735294117647056)}
So what are the take-aways from these results
Rouge-2 values are typically lower than Rouge-1. That’s normal as 2-gram are harder to match than 1-gram
ChatGPT summary is shorter and this might explain why ChatGPT scores are slightly lower than Gemini
In this short article I have shown an end to end example on how to use ROUGE score to evaluate the generated summary quality. In upcoming articles I will use more sophisticated metrics like BLEU and BERT_SCORE.