
LLM-Server on your Laptop , is it possible ?
A Hello World Example


Topics:
Why Local-LLM
Overview of Local-LLM architecture
vLLM serving framework - A Hello world example
One of the LLM-related topics I have great interest in is Local-LLMs frameworks. Simply, this is the set of technologies and skills needed to run, tune, deploy and evaluate Local-LLMs for production-level models.
Why Local LLMs models ? Simply remember the C3P abbreviation : Control , Cost Customization and Privacy :
Control : you have control over which base model to use (LLama , Mistral7B, Open Source GPT family, tiny-llm), given your infrastructure and the task at hand
Cost : Despite the initial overhead for setting up infra and training developers on the solution and how to tune and maintain it, it will pay off once the number of requests to the solution increase and the savings will outweigh the initial cost.
Customization : You can tune the model on your own dataset (Yes, you can : See this tutorial)
Privacy : your data stays on your devices. Simply by sending data to 3rd party AI / LLM provider, you RISK leaking your data (See this article)
Now that I have caught your attention, check this simple architecture through which a local LLM solution can be integrated to your existing solutions and applications.
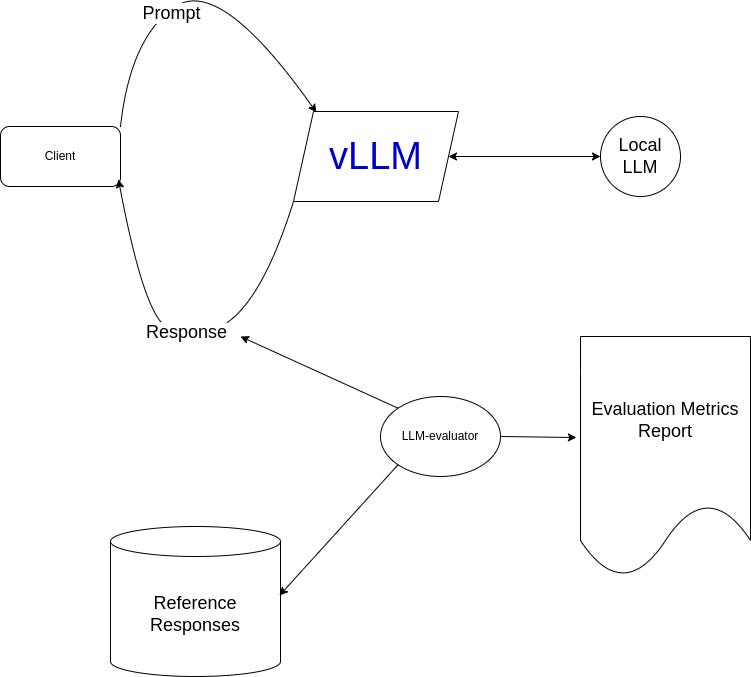
The main components for any local LLM solution :
Local LLM model : as mentioned, one of the dozens of open sources model. Hugging Face is the Walmart of Open-Source LLMs.
Serving layer : this layer is responsible for sending requests to LLM model backend and propagating back response to client. The main metric for these layer is throughput and latency. Usually, they should support batch requests.
LLM-Evaluator : module that validates the “quality” of generated responses. Usually there are two approach : using reference dataset ( benchmark ) for several tasks or using another LLM-as-a Judge.
In this article, as a starting point, we focus on a hello-world example to run a simple local-llm model using vLLM - an hight-throughput and memory framework form serving LLM-models on local infrastructures.
Now I show the details of my small experiment for installing vLLM locally and running a simple prompt against the local model
Platform
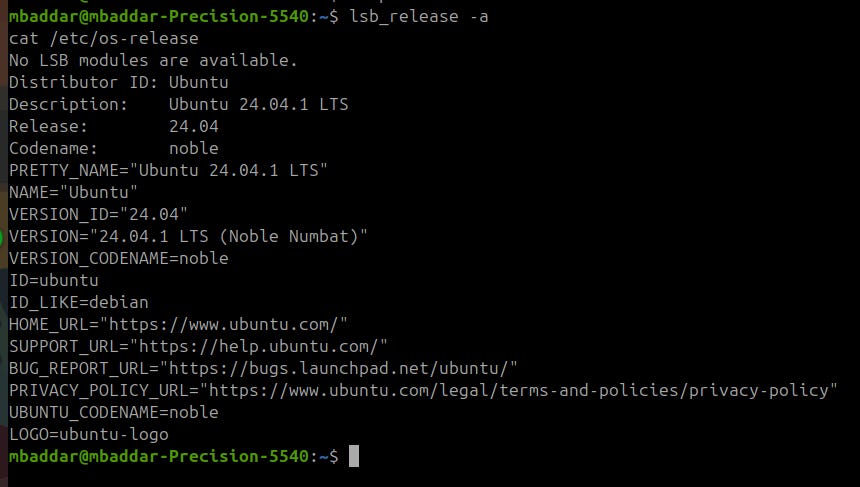
OS
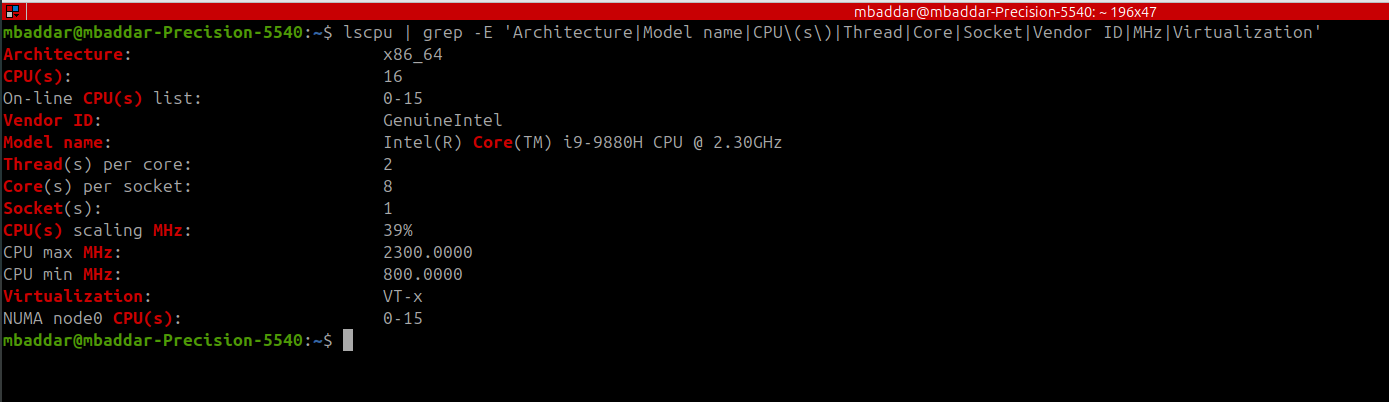
CPU
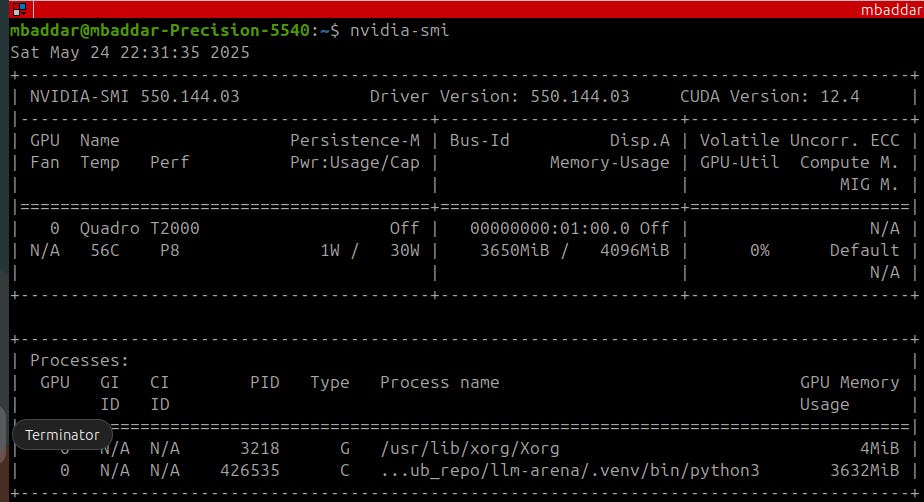
GPU
Installation
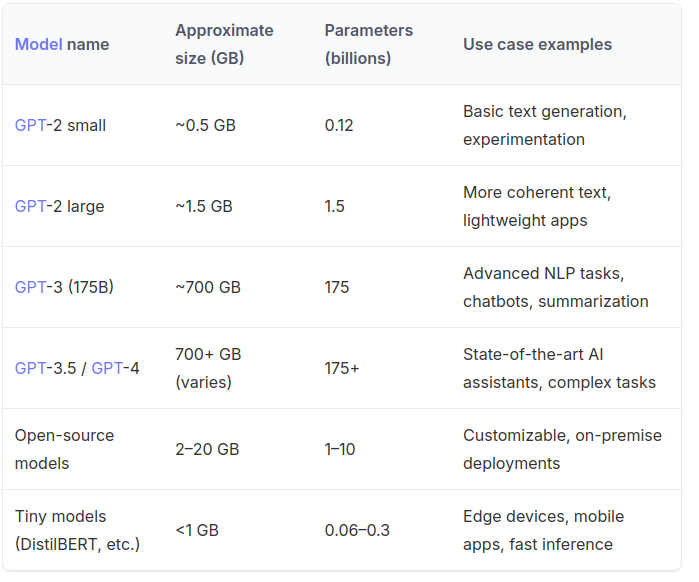
First make sure you have enough disk space for vLLM installation (1 to 2 GB) and around 20GB for ONE LLM model to use (see this table for model sizes)
I have installed it using this simple pip command (source)
pip install vllm --extra-index-url https://download.pytorch.org/whl/cu128Spinning Up Local-LLM Server
Then you can run a local LLM server with a specific model as follows:
python3 -m vllm.entrypoints.openai.api_server --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 --max-model-len 512 --max-num-seqs 1 --dtype float16Explanation of parameters:
( 1 ) --modelThe model to be loaded. It should follow Hugging-Face naming convention. You can search the set of Hugging Face models here.
( 2 ) --max-model-lenThis is the maximum token limit for each model. To learn more about tokens see this article. Simply, you can think of token as 3/4 english word.
( 3 ) --max-num-seqsThis is the max. number of prompts that a model can handle in parallel. We set it to 1 for now as it is a toy example
( 4 ) --dtypeThe data type used by the model : float16,32,64 etc…
I have used —dtype half (float16).With any other option I get the error :
ERROR 05-25 01:48:25 [engine.py:448] ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your Quadro T2000 GPU has compute capability 7.5. You can use float16 instead by explicitly setting the `dtype` flag in CLI, for example: --dtype=half.
For more information , check vLLM getting started document.
Now the server is up and running

Sending Prompt to server
Using curl we can send the following request
curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"prompt": "San Francisco is a",
"max_tokens": 100,
"temperature": 0
}'
And I got the following response
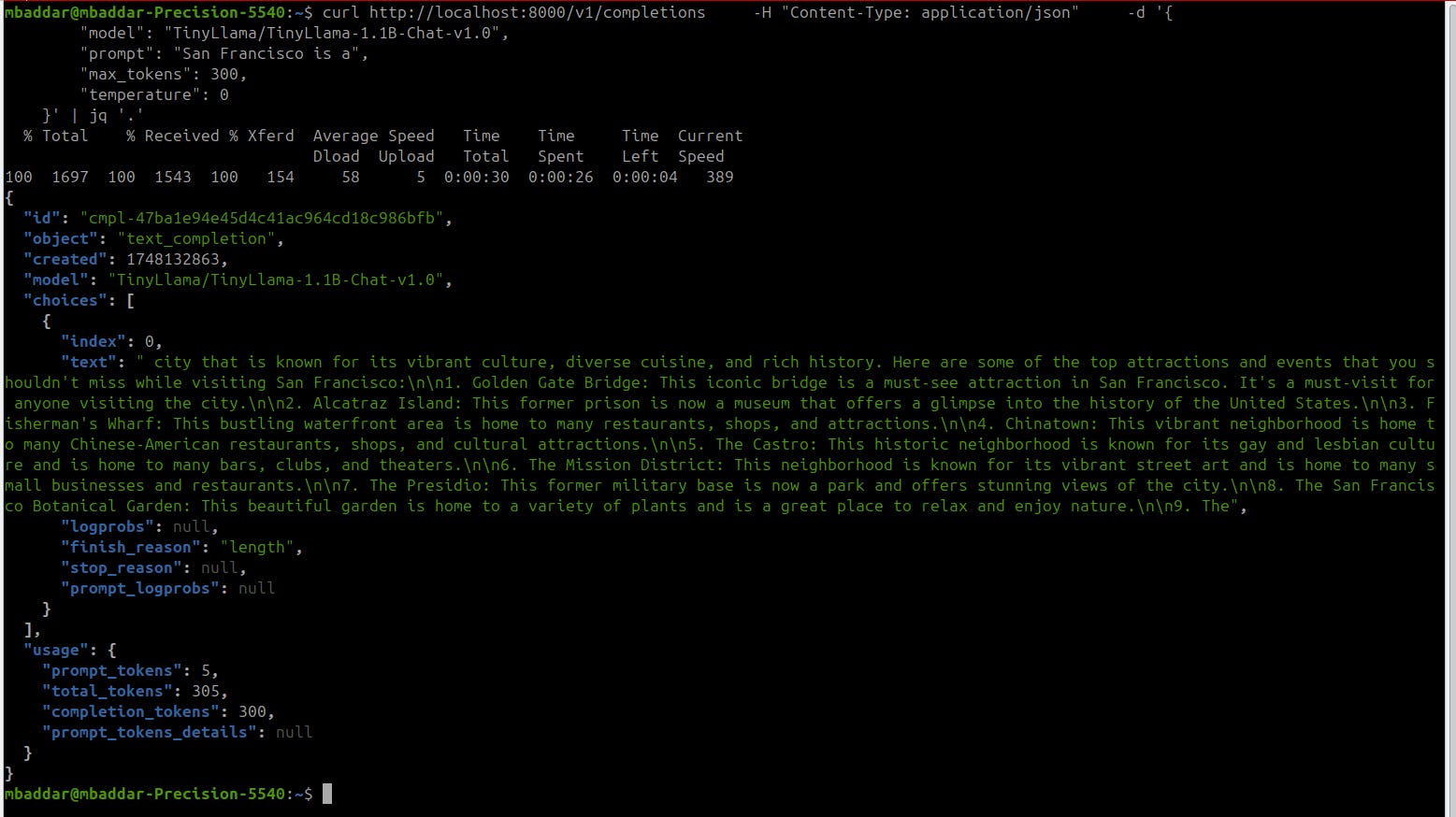
Now we have a minimal working example for a local LLM server that gives “reasonable” response.
Next :
Compare results for different local models for different questions ?
Quick evaluation of the quality of responses.
So stay tuned for the next set of articles.
Subscribe to get our latest articles direct to your inbox
Email me if you need support in LLM-development, deployment or integration with your solution or business process : mbaddar2 [at] gmail [dot] com