
How Generative Models Work?
How can they Speak so well ?

 | Belonging, Identity, Language, Diversity Research Group (BILD)")
Note : This article appeared originally in my Betaflow publication in medium .I will leave the link in the references section below.
AI is all the rage now, especially with Large Language Models that can talk like humans. Cool, right? But aren’t you just a little curious about how they actually work? The concept is pretty straightforward—not easy, since it takes serious engineering and massive resources, but definitely not too intimidating to understand.
If I’ve sparked your curiosity, let’s dive in!
Note: I might throw in a few simple equations, but don’t worry—understanding them isn’t essential to grasp the main ideas.
What is Generative Models
Generative models are systems that predict the chances of seeing something (Y) based on hidden or unknown factors (X).
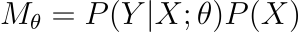
That’s a bit abstract, isn’t it? Let’s look at a real-world example:
Language Generative Models
Imagine we have a vocabulary with |V| words and a sentence of length L, indexed as t = 1, 2, ..., N, where w(t) represents the word at position t in the sentence. Almost all language generative models follow this approach:
They generate a distribution vector.
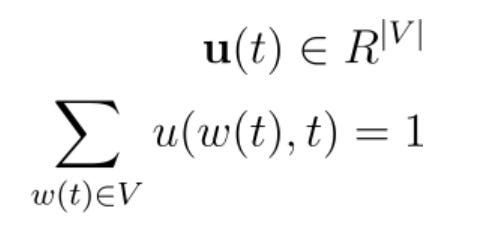
Here’s a simple example: the goal is to generate the distribution vector for t=4, based on the words at positions t=1, 2, and 3. As humans, we know the correct word is “Fast,” but we want the machine to learn this on its own.
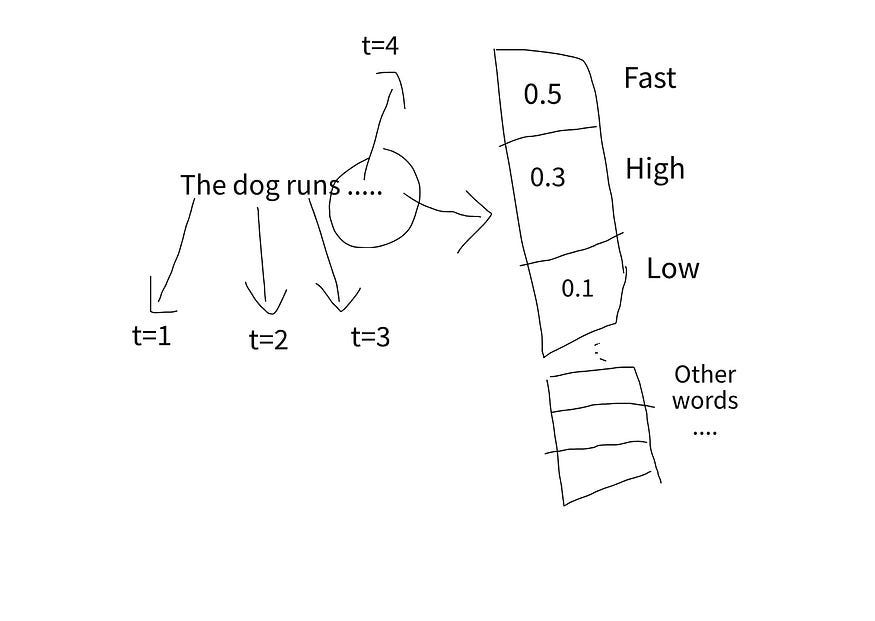
Language models generally learn this in a similar way. Take a look at the following example using a 3-sentence dataset:
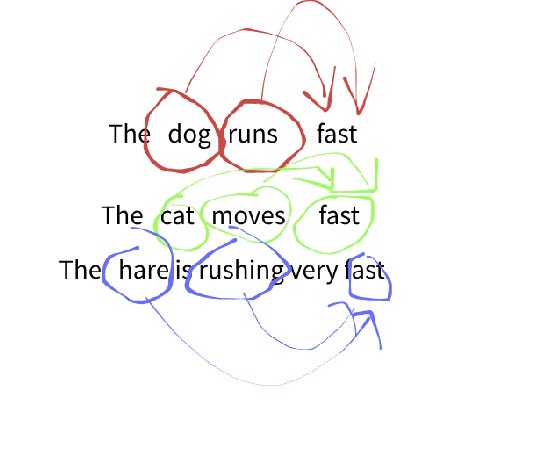
To predict the word “fast” at its position, generative models focus on capturing the “context”—the previous words and their distributions. This is a simplified explanation of what happens behind the scenes.
To dive deeper, explore these topics:
In upcoming articles, I’ll provide more visual explanations of these concepts to help interested readers grasp the key ideas behind them.
The link of the original article on Medium is here.