
Large Language Model to summarize your financial report?
Can you blindly rely on these summaries? Can we measure how good it is ?

In this article:
Why text summarization is crucial for financial analysis.
Definition : How do we define a (good) summary of a text
ROUGE : A simple metric to tell how good a text summary is
Who should be concerned about text summarization ?
Are you a financial analysts overwhelmed by dozens of requests to look at financial statements ? Do you software solution for finance and want help customers increase productivity analyzing hundreds of financial reports, or you are even curious about the application of Large Language Models (LLM) to finance ? Then this article is for you.
What problem does summarization solve in the financial industry ?
Financial reports are typically lengthy, averaging between 100 and 150 pages (source). As a result, reviewing multiple reports and extracting relevant insights for decision-makers is a challenging and time-consuming task. Moreover, the quality of these summaries directly impacts the decisions made. A reliable summarization tool can provide the best of both worlds—enabling faster financial decision-making while ensuring the summaries remain high-quality and informative.
This article aims to assess the quality of text summaries generated by Large Language Models (LLMs) using a simple example to illustrate the concept. If you're interested in learning more about how LLMs summarize text and the different approaches models take to tackle this problem, you can find a list of valuable resources in the reference section.
Definition of the problem
So first things first : what is summarization ?
Summarization (Cambridge definition)
The act of expressing the most important facts or ideas about something or someone in a short and clear form, or a text in which these facts or ideas are expressed
In summary, a summary is a condensed version of a document (text or audio) that retains its most important ideas. In other words, it involves a constraint—reducing the length significantly compared to the original document—while aiming to maximize the amount of useful information preserved.
Many articles cover various metrics by explaining their logic and formulas—but they often stop there. I’ll take a different approach: starting with the simplest metric and exploring it in depth before moving on to more advanced ones in future articles.
ROUGE
Recall-Oriented Understudy for Gisting Evaluation (ROUGE) is a metric to measure how much useful information does the summary contain from the original text.
But before delving into details , let’s try to figure out what “recall” is.
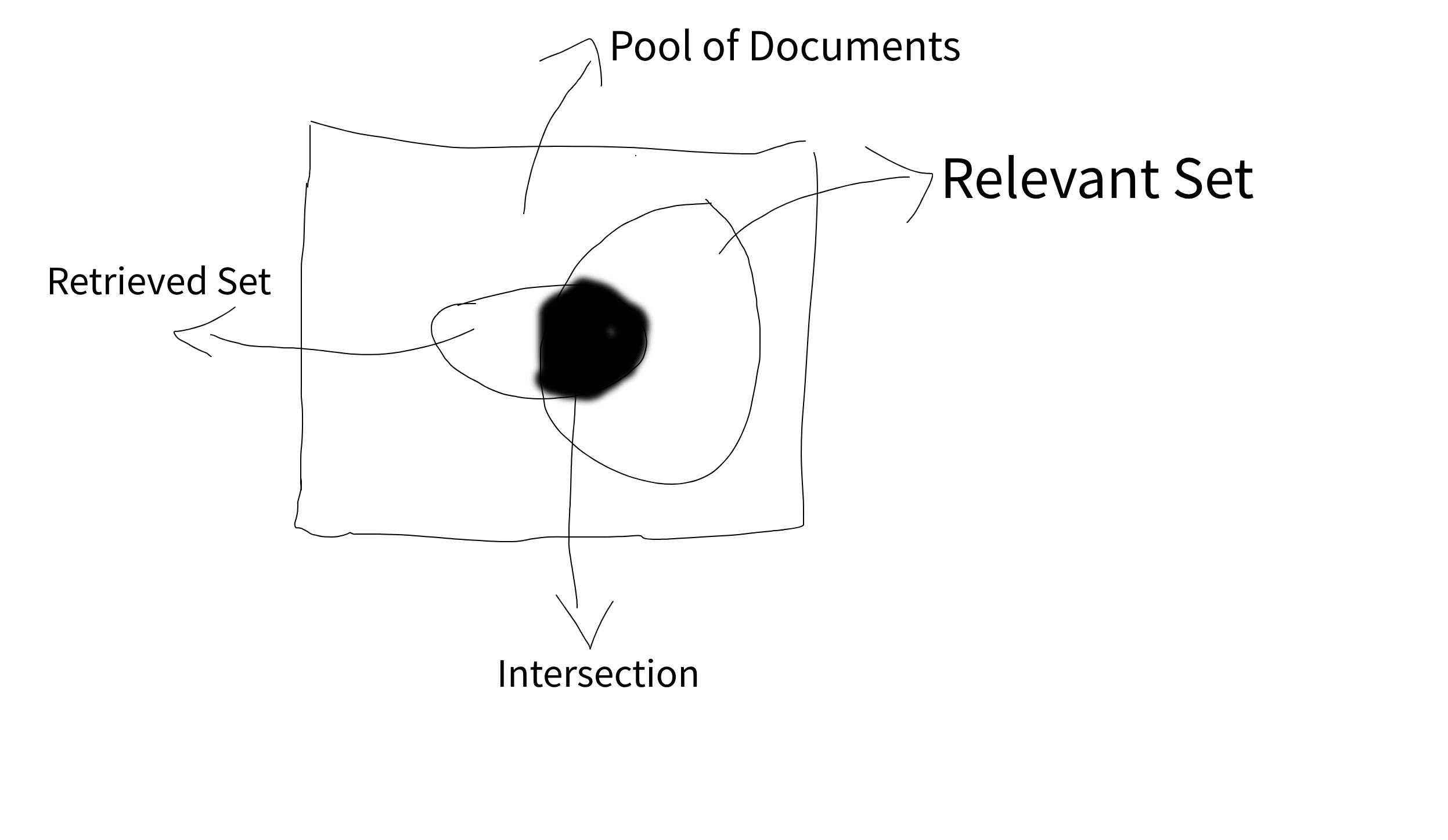
From Information Retrieval branch of computation and information science, any recall measures how many relevant documents are retrieved out of the pool of all relevant documents.
Then recall will be :
Which means the number of documents correctly retrieved of the all the number of relevant documents.
How ROUGE is defined in terms of “Recall” ?
So the term “document” in the recall definition you can find most of articles you can find on the internet can be abstracted to the concept of “Piece of Information” . For example a PDF document, and image, an audio file, a YouTube video, all can be classified as “Pieces of Information” .
Now we have provided the needed abstraction, we for convenience let’s call a piece information I . Then recall of any “Information System” can be
The number of retrieved and relevant pieces of information over the total number of all relevant pieces of information.
So how can we define a “Piece of Information” ?
So in the context of summarization, what can be a good choice of “Piece of information” . The developers of ROUGE metric had chosen N-grams , a simple yet effective concept in natural language processing.
Lets illustrate by example. Consider this simple sentence :
I love eating cheeseburger
N-Gram is the set of “N-words grouping”. For example, 1-Gram will be :
I
love
eating
cheeseburger
The 2-Gram will be
I love
love eating
eating cheeseburger
The 3-gram will be
I love eating
love eating cheeseburger
and so on.
Of course, usually we don’t consider all words in the original text, but the most important ones to generate N-grams. How do we know most important words ? An importance index like “Term-Frequency Inverse Document Frequency (TF-IDF” is used. Simply we strip down the original large text to the sent of sentences having import words, which have high values. However, this processing is out of the scope of this articles.
Now we have a good definition for N-Gram , which will be our realization to the “Piece of information” concept, The Rouge-N definition will be :
Number of N-Grams in the summary and the original text (relevant N-Grams) over the number of N-Grams in the original text
Now let’s take a toy example.
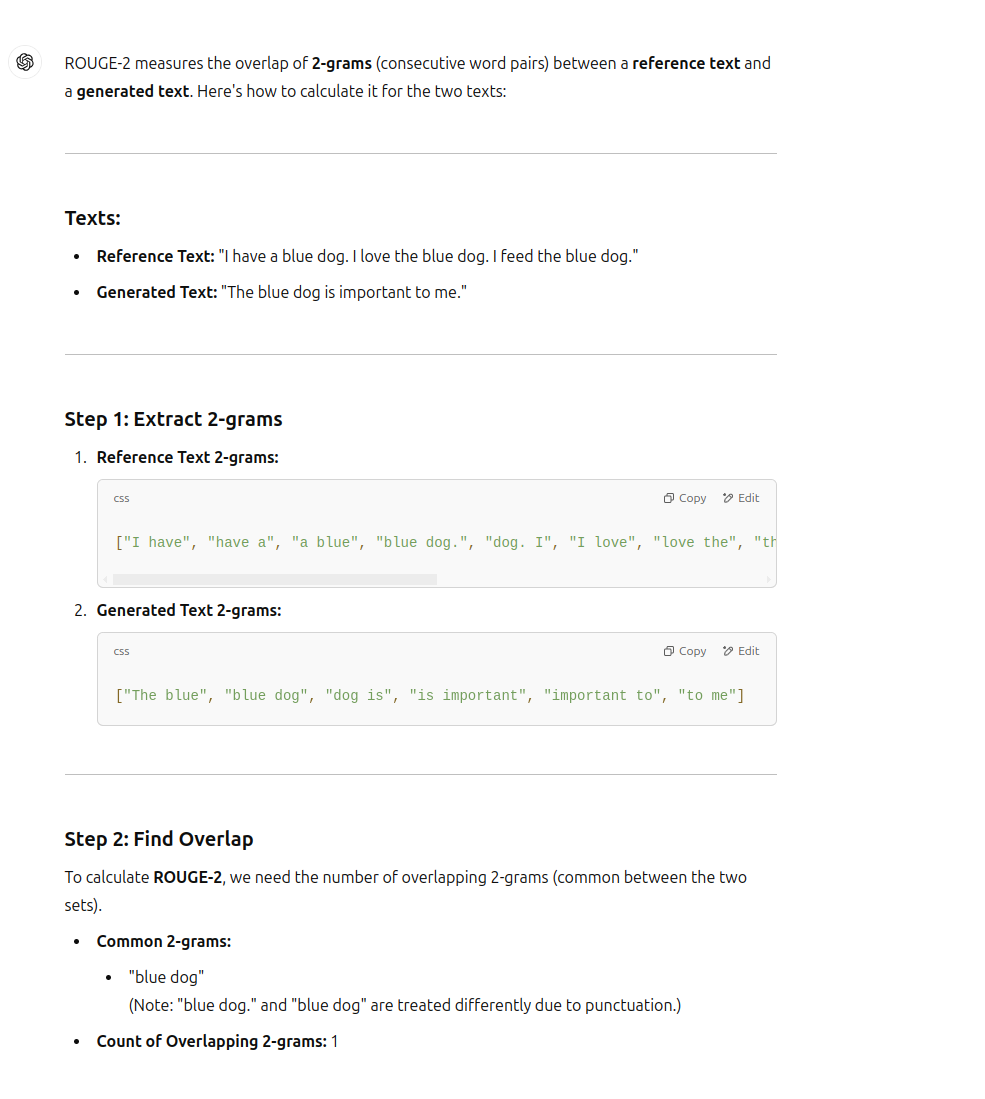
Original text :
I have a blue dog. I love the blue dog. I feed the blue dog
Summary :
The blue dog is important to me
And instead of doing manual computation which is a donkey work, let’s dedicate it to ChatGPT


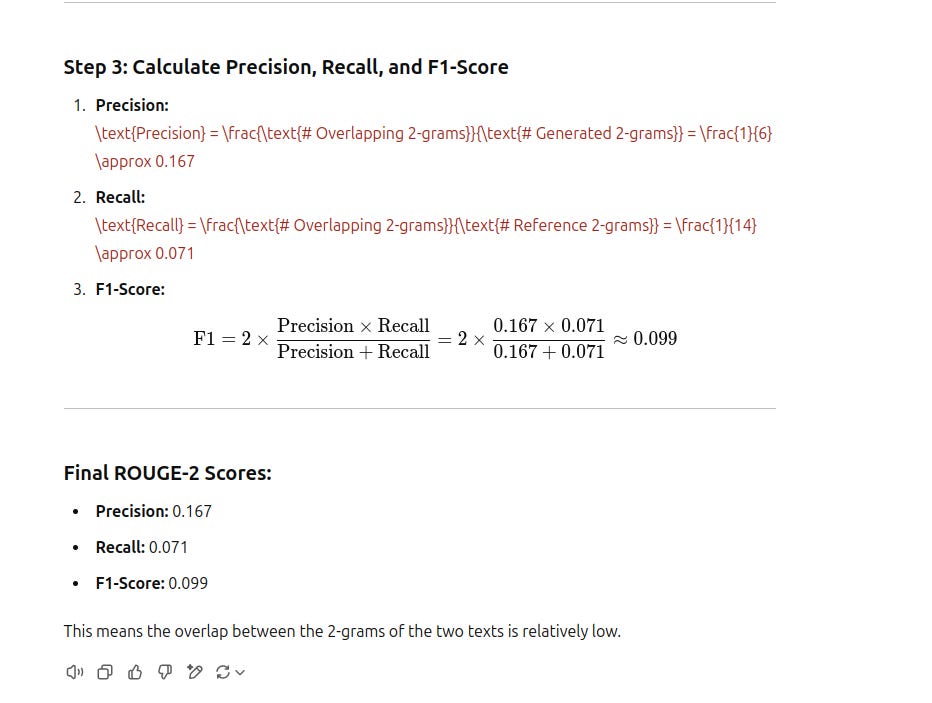
Now we have a complete overview of how ROUGE is calculated. In the next article, I will show a real-world example to evaluate how ROUGE can be used to evaluate financial report summarization. Stay tuned