
Transformers Meet Classical XGB
A simple sentiment analysis experiment

What you can expect in this article
Overview about the problem of sentiment analysis (classifying text data)
What are embeddings model and a bird eye overview about how they work
A python code implementing basic “XGB_Classifer + Embeddings” classification system to conduct sentiment classification on Amazon Review dataset
An illustration of the code with observations about the output
The Problem
Given a set of free text (a set of sentences, usually not very long) L = {S1,S2,…,Sn} and for each sentence we have a positive and negative label, we want to build a classification system that classify each sentence as correct as possible. The main metric for this system the the Area Under Curve (Reference 1).
The classical real world application for this problem is the sentiment analysis :
Given a set of “feedbacks” where each feedback consists of a set of a “few” sentences , it will help to identify if this feedback is positive or negative. This can help, for example to predict the likeability of purchase for this product, hence control how it is ranked.

On an advanced level, analyzing feedback text can give insights about (1) factors based on which people decide how good or bad the product is, for ex. price, quality, speed of shipment (2) for each product, what the values of these factors. However, this is out of scope of this article
The Solution
This section I will divide into some background and then realization of the solution
» Background
As it is well known, Transformers (which is a special architecture type that understands text) is the backbone of most LLMs. Pretrained transformers can be a good tool to “embed” feedback text to a fixed length features vectors.
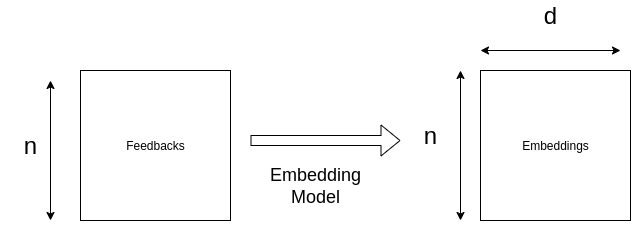
So how brilliant pretrained transformers convert a set of n feedback, where each feedback has variable number of tokens (m_i , 1<=i<=n), to a fixed dimensions embeddings matrix E of dimensions n x d ??
Let me give an outline of how it works, to delve further into details, see Ref #2,3
Each text T_i , 1<=i<=n , is tokenized into set m_i tokens : “I love this product” →”I” , “Love” , “This” , “Product” .
Tokens are cleaned and normalized
For each pretrained model, it has a core “token-embedding-matrix” , call it M.
M has dimensions of kxd where k is the number of most common tokens this embedding model is trained (for ex it can be 30,000 or 50,000 tokens). The embedding dimension is an arbitrary number that forms the hyperspace of the embeddings. The higher the dimension, the more complex is the assumption about how the context surrounding this word is (See Ref # 2 for more details)Each token u_ij (the jth token in the ith piece of text, 1<=j<=m_i for each i)
is mapped to a number (using some predesigned magic function or so) that maps each token to the “row” number in the token-embedding-matrix M , u_ij → s . Then the embedding for this token is M[s,:] which is a d dimensional vectorFor all m_i tokens in text T_i we have an embedding vector e1,e2,..,e_mi each of which is of dimension d . If we stach all of these embedding vectors , row wise , we end with a matrix of dimension m_i x d.
But we want to map each text T_i to a vector of dimension d not a matrix of dimension m_i x d. The solution is to apply some pooling method to squash the the matrix column wise from m_i x d to a vector d . The most straight forward approach is average pooling (Ref 3 and 4)
No we have set of n pieces of text (T_i , i=1,..,n) to an embedding matrix E of dimension n x d (As in Figure 2)
However one question arises , how this magic embedding matrix is trained ?? In summary, the embedding matrix is the “Weight” matrix used to make each word able to predict the surrounding text in the embedding hyperspace of dimension d. This training depends on
What text corpus is this embedding model using to train its embedding matrix
What is the definition of “context” used in training. For example, the context might be the surrounding words around each token
What kind of loss function is used
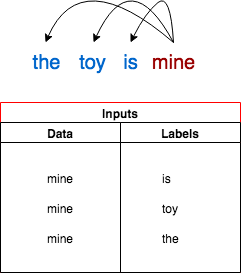
In figure 3 a naive example on how we can “assume” some target to use for training the embedding model to get the matrix. Given millions of real world text , we will try to set the “encoding” of each token to help make this word able to predict the context around it , i.e. nearby words.
For more details on how Embedding Matrices are generated , check the wonderful tutorial in Ref 2.
Given the conversion from free text to numerical matrix , we can directly apply classical ML classifier for sentiment analysis. In this article I use XGBClassifier, why ? (1) Well studied and commonly used among ML practitioners (2) Well supported by python (3) Easy to understand and to extract metadata bout the model , like feature importance. (See Ref 5)
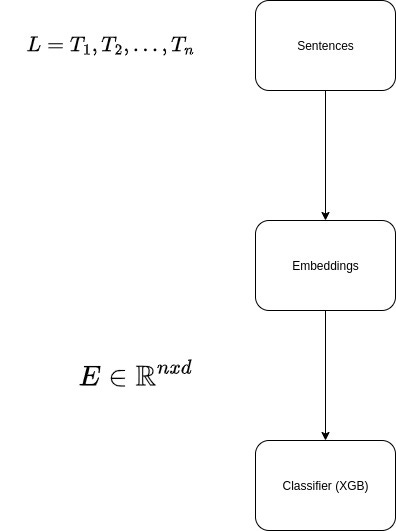
» Implementation
In this part I will provide a simple working code that builds a sentiment analysis over amazon product review data
Data : Amazon products sentiment analysis data (~3M samples for training , 400K for testing). See Ref 6
Each sample has a “cleaned” text of review and two labels : Labell_1 and Label_2. Label_1 is a bad review when the rating is 1 or 2. Label_2 is a good review if rating is 4 or 5. Rating of 3 is neutral and removed from data
With that said , here is the working code
_______
import bz2
from argparse import ArgumentParser
from typing import Union
import matplotlib.pyplot as plt
import numpy as np
import torch.cuda
from sentence_transformers import SentenceTransformer
from loguru import logger
import pandas as pd
from sklearn.decomposition import TruncatedSVD
from sklearn.metrics import roc_auc_score
from tqdm import tqdm
from xgboost import XGBClassifier
from datetime import datetime
def read_amazon_data(file_path: str, n_lines: Union[int, None] = None):
# Each line starts with a label followed by the review text
logger.info(f"Reading lines")
with bz2.open(file_path, mode="rt", encoding="utf-8", errors="ignore") as f:
if n_lines is None:
lines = f.readlines()
else:
lines = []
for i, line in tqdm(enumerate(f), desc="read-lines"):
lines.append(line)
if i == n_lines - 1:
break
lines_dicts = []
sep = " "
for line in lines:
tokens = line.split(sep)
label = tokens[0]
sentence = sep.join(tokens[1:])
lines_dicts.append({"label": label, "sentence": sentence})
df = pd.DataFrame.from_records(data=lines_dicts)
df["label"] = df["label"].apply(lambda x: 1 if x == "__label__2" else 0)
return df
def get_xgb_emb_auc(bst: XGBClassifier, X_train: np.ndarray, X_test: np.ndarray, y_train: np.ndarray,
y_test: np.ndarray):
# fit model
bst.fit(X_train, y_train)
# make predictions
y_pred_proba = bst.predict_proba(X_test)[:, 1]
auc = roc_auc_score(y_test, y_pred_proba)
return auc
parser = ArgumentParser()
parser.add_argument("--train_data_path", type=str, required=True)
parser.add_argument("--test_data_path", type=str, required=True)
parser.add_argument("--embedding-model-name", type=str, required=True)
parser.add_argument("--n-train", type=int, required=True)
parser.add_argument("--n-test", type=int, required=True)
parser.add_argument("--dim-fraction-step", type=float, required=True)
args = parser.parse_args()
if __name__ == "__main__":
logger.info(f"Is cuda available {torch.cuda.is_available()}")
df_train = read_amazon_data(file_path=args.train_data_path, n_lines=args.n_train)
df_test = read_amazon_data(file_path=args.test_data_path, n_lines=args.n_test)
y_train = df_train["label"]
y_test = df_test["label"]
logger.info(f"Embedding Model = {args.embedding_model_name}")
train_sentences = df_train["sentence"].to_list()
test_sentences = df_test["sentence"].to_list()
device = torch.device("cuda")
embeddings_model = SentenceTransformer(model_name_or_path=args.embedding_model_name, device="cuda")
bst = XGBClassifier(n_estimators=2, max_depth=2, learning_rate=1, objective='binary:logistic')
logger.info(f"Classifier Model = {bst}")
# get embeddings model meta data
embeddings_dim = embeddings_model.get_sentence_embedding_dimension()
logger.info(f"Embeddings dim = {embeddings_dim}")
logger.info(
f"Applying embeddings to train sentences (n={args.n_train}) and test sentences (n={args.n_test}) sentences")
start_timestamp = datetime.now()
train_embeddings = embeddings_model.encode(sentences=train_sentences,show_progress_bar=True)
end_timestamp = datetime.now()
train_embeddings_generation_time = (end_timestamp - start_timestamp).seconds
start_timestamp = datetime.now()
test_embeddings = embeddings_model.encode(sentences=test_sentences,show_progress_bar=True)
end_timestamp = datetime.now()
test_embeddings_generation_time = (end_timestamp - start_timestamp).seconds
# get full rank (dim) auc
auc_data = []
auc = get_xgb_emb_auc(bst=bst, X_train=train_embeddings, X_test=test_embeddings, y_train=y_train, y_test=y_test)
logger.info(f"AUC for full-dim features (dim = {embeddings_dim}), = {auc}")
auc_data.append((embeddings_dim, auc))
dim_step = int(args.dim_fraction_step * embeddings_dim)
target_dim = embeddings_dim - dim_step
while target_dim > 0:
assert target_dim < args.n_train
assert target_dim < args.n_test
logger.info(f"Lowering dimension from {embeddings_dim} to {target_dim}")
svd_model = TruncatedSVD(n_components=target_dim, n_iter=7, random_state=42)
train_embeddings_low_dim = svd_model.fit_transform(X=train_embeddings)
test_embeddings_low_dim = svd_model.fit_transform(X=test_embeddings)
auc = get_xgb_emb_auc(bst=bst, X_train=train_embeddings_low_dim,
X_test=test_embeddings_low_dim, y_train=y_train, y_test=y_test)
logger.info(f"After lowering dimension from {embeddings_dim} to {target_dim}, auc = {auc}")
auc_data.append((target_dim, auc))
target_dim -= dim_step
x, y = zip(*auc_data)
# plot
plt.plot(x, y, linestyle="-") # or plt.plot(x, y) if you want a line
plt.xlabel(f"n_features")
plt.ylabel("classifier auc")
plt.title(f"Embedding model={args.embedding_model_name},\n"
f"Classifier=XGB,n_train={args.n_train},n_test={args.n_test}")
plt.grid(True)
plt.show()
plt.savefig(f"xgb_embeddings_{args.embedding_model_name}.png")_______
In summary , the code does the following
It loads the amazon train and test data
It uses the sentences transforms library (Ref 7) to load variety of pretrained embedding models, the model name is passed as a parameter
It creates a simple XGBclassifier
The pretrained models are applied for a “sample” of the training and test text. GPU is used
After having the features matrices X_train X_test and targets y_train and y_test , we train the classifier, test it against test data and calculate AUC
Extra : due to the high dimensionality , I tested compressing high-dim X_train and X_test with Singular Value Decomposition (SVD, Ref 8) , to see if lower dimension embedding can give the same AUC
SVD https://en.wikipedia.org/wiki/Singular_value_decomposition
Here is a sample run
python xgb_with_embeddings.py --train_data_path train.ft.txt.bz2 --test_data_path test.ft.txt.bz2 --embedding-model-name <MODEL_NAME> --n-train 100_000 --n-test 10_000 --dim-fraction-step 0.2
I have tried two models
all-MiniLM-L6-v2
all-MiniLM-L12-v2
Why these two models ? Both are relatively small models with which I managed to get results on my laptop
Here is a ChatGPT generated table comparing two models (See also Ref 8):

Now let’s present the code output.
all-MiniLM-L6-v2
2025-08-29 01:43:39.705 | INFO | __main__:<module>:78 - Embedding Model = all-MiniLM-L6-v2
2025-08-29 01:43:44.327 | INFO | __main__:<module>:84 - Classifier Model = XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
feature_weights=None, gamma=None, grow_policy=None,
importance_type=None, interaction_constraints=None,
learning_rate=1, max_bin=None, max_cat_threshold=None,
max_cat_to_onehot=None, max_delta_step=None, max_depth=2,
max_leaves=None, min_child_weight=None, missing=nan,
monotone_constraints=None, multi_strategy=None, n_estimators=2,
n_jobs=None, num_parallel_tree=None, ...)
2025-08-29 01:43:44.327 | INFO | __main__:<module>:87 - Embeddings dim = 384
2025-08-29 01:43:44.327 | INFO | __main__:<module>:88 - Applying embeddings to train sentences (n=100000) and test sentences (n=10000) sentences
Batches: 100%|██████████| 3125/3125 [05:19<00:00, 9.78it/s]
Batches: 100%|██████████| 313/313 [00:40<00:00, 7.70it/s]
2025-08-29 01:49:49.794 | INFO | __main__:<module>:103 - AUC for full-dim features (dim = 384), = 0.712645583489681
2025-08-29 01:49:49.794 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 308
2025-08-29 01:50:05.474 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 308, auc = 0.29819621263289553
2025-08-29 01:50:05.474 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 232
2025-08-29 01:50:23.519 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 232, auc = 0.29819621263289553
2025-08-29 01:50:23.519 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 156
2025-08-29 01:50:35.937 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 156, auc = 0.29819621263289553
2025-08-29 01:50:35.937 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 80
2025-08-29 01:50:44.432 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 80, auc = 0.29819621263289553
2025-08-29 01:50:44.433 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 4
2025-08-29 01:50:46.379 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 4, auc = 0.6147143164477799
Process finished with exit code 0all-MiniLM-L12-v2
2025-08-29 02:32:41.058 | INFO | __main__:<module>:78 - Embedding Model = all-MiniLM-L12-v2
2025-08-29 02:32:45.620 | INFO | __main__:<module>:84 - Classifier Model = XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
feature_weights=None, gamma=None, grow_policy=None,
importance_type=None, interaction_constraints=None,
learning_rate=1, max_bin=None, max_cat_threshold=None,
max_cat_to_onehot=None, max_delta_step=None, max_depth=2,
max_leaves=None, min_child_weight=None, missing=nan,
monotone_constraints=None, multi_strategy=None, n_estimators=2,
n_jobs=None, num_parallel_tree=None, ...)
2025-08-29 02:32:45.620 | INFO | __main__:<module>:87 - Embeddings dim = 384
2025-08-29 02:32:45.620 | INFO | __main__:<module>:88 - Applying embeddings to train sentences (n=100000) and test sentences (n=10000) sentences
Batches: 100%|██████████| 3125/3125 [07:55<00:00, 6.57it/s]
Batches: 100%|██████████| 313/313 [00:58<00:00, 5.38it/s]
2025-08-29 02:41:44.385 | INFO | __main__:<module>:103 - AUC for full-dim features (dim = 384), = 0.7219352095059413
2025-08-29 02:41:44.385 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 308
2025-08-29 02:41:57.273 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 308, auc = 0.7188832420262664
2025-08-29 02:41:57.273 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 232
2025-08-29 02:42:09.236 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 232, auc = 0.7188463989993746
2025-08-29 02:42:09.236 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 156
2025-08-29 02:42:21.646 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 156, auc = 0.7188463989993746
2025-08-29 02:42:21.646 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 80
2025-08-29 02:42:28.789 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 80, auc = 0.7188463989993746
2025-08-29 02:42:28.789 | INFO | __main__:<module>:111 - Lowering dimension from 384 to 4
2025-08-29 02:42:30.505 | INFO | __main__:<module>:117 - After lowering dimension from 384 to 4, auc = 0.6028136985616009
Process finished with exit code 0Observations
AUC for 2 models almost the same (0.72) for full-dimension embeddings (dim=384)
V12 model is more robust to dimension compression than V6 model (need more investigation)
AUC value means that the classifier provides “acceptable discrimination” (see Fig. 6). Keep in mind that this is a naive PoC to test embeddings + XGB classifier

Give these results we can conclude that Embeddings + XGB_Classifier can give a decent classification system for text data.
The work done here is inspired by the tutorial in Ref 10.
References
AUC and ROC
https://developers.google.com/machine-learning/crash-course/classification/roc-and-aucEmbeddings : A Matrix of Meaning
https://petuum.medium.com/embeddings-a-matrix-of-meaning-4de877c9aa27Pooling in Embeddings
https://medium.com/@suvasism/pooling-in-embedding-16781aacfb12Sentence Transformer Modules
https://www.sbert.net/docs/package_reference/sentence_transformer/models.html
https://www.sbert.net/docs/package_reference/sentence_transformer/models.html#sentence_transformers.models.PoolingXGB Classifiers
https://www.geeksforgeeks.org/machine-learning/xgbclassifier/Amazon Review Dataset
https://www.kaggle.com/datasets/bittlingmayer/amazonreviewsSentences Transforms Library
https://sbert.net/
Models
https://www.sbert.net/docs/sentence_transformer/pretrained_models.htmlEmbedding models specs
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2Hosmer, Lemeshow & Sturdivant (2013): Applied Logistic Regression (3rd ed.). Wiley.
https://dl.icdst.org/pdfs/files4/7751d268eb7358d3ca5bd88968d9227a.pdfCombining XGBoost and Embeddings: Hybrid Semantic Boosted Trees?
https://machinelearningmastery.com/combining-xgboost-and-embeddings-hybrid-semantic-boosted-trees/